Dataset
- annotations
- train.csv
- val.csv
- actionlist.pbtxt
- train_excluded_timestamps.csv
- val_excluded_timestamps.csv
- dense_proposals_train.pkl
- dense_proposals_val.pkl
- rawframes
- video_0
- frame_0
- video_0
- frame_lists
- train.csv
- val.csv
Pytorch 1.8.0,python 3.8,CUDA 11.1.1
# ffmpeg用于处理视频
conda install x264 ffmpeg -c conda-forge -y
# 其余需要的库
git clone https://github.com/Shu-Ang/myAVA.git
cd myAVA
pip install -r ./yolovDeepsort/requirements.txt
# 下载预训练模型 (如果速度太慢可以在本地下载上传服务器到指定目录)
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt -O ./yolovDeepsort/yolov5/yolov5s.pt
mkdir -p ~/.config/Ultralytics/
wget https://ultralytics.com/assets/Arial.ttf -O ~/.config/Ultralytics/Arial.ttf
wget https://drive.google.com/drive/folders/1xhG0kRH1EX5B9_Iz8gQJb7UNnn_riXi6 -O ./yolovDeepsort/deep_sort_pytorch/deep_sort/deep/checkpoint/ckpt.t7 分别将训练集视频和验证集视频上传至./Dataset/train_videos和./Dataset/val_videos目录下,一次可以对多个视频进行处理
bash ./step1.sh train $gpu
或者
bash ./step1.sh val $gpu
# 其中$gpu为 0 1 2..之后将./Dataset/choose_frames.zip下载到本地并解压,用于下一步标注操作
下载via工具https://www.robots.ox.ac.uk/~vgg/software/via/downloads/via3/via-3.0.13.zip
点击标注工具中的: via_image_annotator.html

下图是via的界面,1代表添加图片,2代表添加标注文件

导入图片,打开标注文件(*_proposal.json),最后结果:
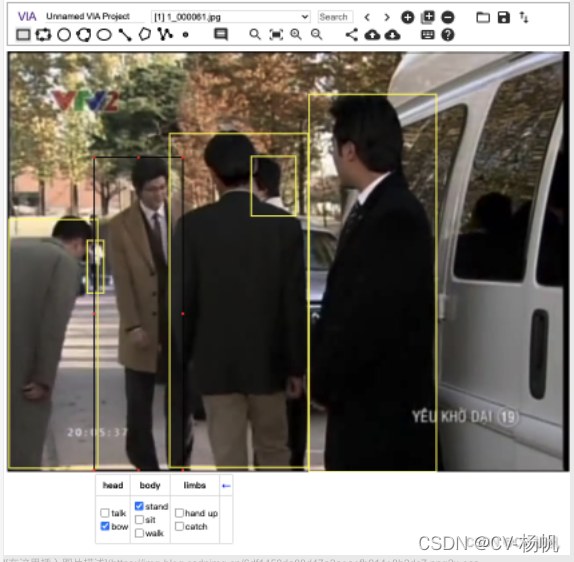
标注完成后,导出json并命名为videoname_finish.json,上传./Dataset/train_finish/或./Dataset/val_finish(这个_finish.json文件一定要保留,如果出错可以接着标注)
bash ./step2.sh train $gpu
或者
bash ./step2.sh val $gpu
# 其中$gpu为 0 1 2..之后会在Dataset目录下生成如下结构:
- annotations
- train.csv
- val.csv
- actionlist.pbtxt
- train_excluded_timestamps.csv
- val_excluded_timestamps.csv
- dense_proposals_train.pkl
- dense_proposals_val.pkl
- rawframes
- video_0
- frame_0
- video_0
其中train.csv和val.csv结构如下:
| videoID | sec | x1 | y1 | x2 | y2 | actionID | personID |
|---|
python ./utils/flip.py该操作会将rawframes目录下所有frame和对应的标注框进行水平翻转
python ./utils/generate_framelists.py该操作会在Dataset目录下生成
- frame_lists
- train.csv
- val.csv
注意!开始下一次标注之前务必执行clean1.sh和clean2.sh以删除上次标注的中间输出。
如果使用mmaction2框架进行训练,则需要用到*_proposals_*.pkl
cd /home
pip install mmcv-full==1.3.17 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html
pip install moviepy
pip install opencv-contrib-python==4.10.0.84
git clone https://gitee.com/YFwinston/mmaction2_YF.git
cd mmaction2_YF
pip install -r requirements/build.txt
pip install -v -e .
mkdir -p ./data/ava
cd ..
git clone https://gitee.com/YFwinston/mmdetection.git
cd mmdetection
pip install -r requirements/build.txt
pip install -v -e .
cd ../mmaction2_YF
wget https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_2x_coco/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth -P ./Checkpionts/mmdetection/
wget https://download.openmmlab.com/mmaction/recognition/slowfast/slowfast_r50_8x8x1_256e_kinetics400_rgb/slowfast_r50_8x8x1_256e_kinetics400_rgb_20200716-73547d2b.pth -P ./Checkpionts/mmaction/
cd /xxx/mmaction2_YF/configs/detection/ava/
touch my_slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb.py
内容如下:
# model setting
model = dict(
type='FastRCNN',
backbone=dict(
type='ResNet3dSlowFast',
pretrained=None,
resample_rate=8,
speed_ratio=8,
channel_ratio=8,
slow_pathway=dict(
type='resnet3d',
depth=50,
pretrained=None,
lateral=True,
conv1_kernel=(1, 7, 7),
dilations=(1, 1, 1, 1),
conv1_stride_t=1,
pool1_stride_t=1,
inflate=(0, 0, 1, 1),
spatial_strides=(1, 2, 2, 1)),
fast_pathway=dict(
type='resnet3d',
depth=50,
pretrained=None,
lateral=False,
base_channels=8,
conv1_kernel=(5, 7, 7),
conv1_stride_t=1,
pool1_stride_t=1,
spatial_strides=(1, 2, 2, 1))),
roi_head=dict(
type='AVARoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor3D',
roi_layer_type='RoIAlign',
output_size=8,
with_temporal_pool=True),
bbox_head=dict(
type='BBoxHeadAVA',
in_channels=2304,
num_classes=7, # 这里的类别数等于动作数 + 1(还有一个无动作)
multilabel=True,
dropout_ratio=0.5)),
train_cfg=dict(
rcnn=dict(
assigner=dict(
type='MaxIoUAssignerAVA',
pos_iou_thr=0.9,
neg_iou_thr=0.9,
min_pos_iou=0.9),
sampler=dict(
type='RandomSampler',
num=32,
pos_fraction=1,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=1.0,
debug=False)),
test_cfg=dict(rcnn=dict(action_thr=0.002)))
dataset_type = 'AVADataset'
# 数据集路径
data_root = '/home/zhangshuang/myAVA/Dataset/rawframes'
anno_root = '/home/zhangshuang/myAVA/Dataset/annotations'
ann_file_train = f'{anno_root}/train.csv'
ann_file_val = f'{anno_root}/val.csv'
exclude_file_train = f'{anno_root}/train_excluded_timestamps.csv'
exclude_file_val = f'{anno_root}/val_excluded_timestamps.csv'
label_file = f'{anno_root}/action_list.pbtxt'
proposal_file_train = (f'{anno_root}/dense_proposals_train.pkl')
proposal_file_val = f'{anno_root}/dense_proposals_val.pkl'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_bgr=False)
train_pipeline = [
dict(type='SampleAVAFrames', clip_len=32, frame_interval=2),
dict(type='RawFrameDecode'),
dict(type='RandomRescale', scale_range=(256, 320)),
dict(type='RandomCrop', size=256),
dict(type='Flip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW', collapse=True),
# Rename is needed to use mmdet detectors
dict(type='Rename', mapping=dict(imgs='img')),
dict(type='ToTensor', keys=['img', 'proposals', 'gt_bboxes', 'gt_labels']),
dict(
type='ToDataContainer',
fields=[
dict(key=['proposals', 'gt_bboxes', 'gt_labels'], stack=False)
]),
dict(
type='Collect',
keys=['img', 'proposals', 'gt_bboxes', 'gt_labels'],
meta_keys=['scores', 'entity_ids'])
]
# The testing is w/o. any cropping / flipping
val_pipeline = [
dict(type='SampleAVAFrames', clip_len=32, frame_interval=2),
dict(type='RawFrameDecode'),
dict(type='Resize', scale=(-1, 256)),
dict(type='Normalize', **img_norm_cfg),
dict(type='FormatShape', input_format='NCTHW', collapse=True),
# Rename is needed to use mmdet detectors
dict(type='Rename', mapping=dict(imgs='img')),
dict(type='ToTensor', keys=['img', 'proposals']),
dict(type='ToDataContainer', fields=[dict(key='proposals', stack=False)]),
dict(
type='Collect',
keys=['img', 'proposals'],
meta_keys=['scores', 'img_shape'],
nested=True)
]
data = dict(
#videos_per_gpu=9,
#workers_per_gpu=2,
videos_per_gpu=5,
workers_per_gpu=2,
val_dataloader=dict(videos_per_gpu=1),
test_dataloader=dict(videos_per_gpu=1),
train=dict(
type=dataset_type,
ann_file=ann_file_train,
exclude_file=exclude_file_train,
pipeline=train_pipeline,
label_file=label_file,
proposal_file=proposal_file_train,
person_det_score_thr=0.9,
data_prefix=data_root,
start_index=1,),
val=dict(
type=dataset_type,
ann_file=ann_file_val,
exclude_file=exclude_file_val,
pipeline=val_pipeline,
label_file=label_file,
proposal_file=proposal_file_val,
person_det_score_thr=0.9,
data_prefix=data_root,
start_index=1,))
data['test'] = data['val']
#optimizer = dict(type='SGD', lr=0.1125, momentum=0.9, weight_decay=0.00001)
optimizer = dict(type='SGD', lr=0.0125, momentum=0.9, weight_decay=0.00001)
# this lr is used for 8 gpus
optimizer_config = dict(grad_clip=dict(max_norm=40, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
step=[10, 15],
warmup='linear',
warmup_by_epoch=True,
warmup_iters=5,
warmup_ratio=0.1)
#total_epochs = 20
total_epochs = 100
checkpoint_config = dict(interval=1)
workflow = [('train', 1)]
evaluation = dict(interval=1, save_best='[email protected]')
log_config = dict(
interval=20, hooks=[
dict(type='TextLoggerHook'),
])
dist_params = dict(backend='nccl')
log_level = 'INFO'
work_dir = ('./work_dirs/ava/'
'slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb')
load_from = ('https://download.openmmlab.com/mmaction/recognition/slowfast/'
'slowfast_r50_4x16x1_256e_kinetics400_rgb/'
'slowfast_r50_4x16x1_256e_kinetics400_rgb_20200704-bcde7ed7.pth')
resume_from = None
find_unused_parameters = Falsecd /xxx/mmaction2_YF
python tools/train.py configs/detection/ava/my_slowfast_kinetics_pretrained_r50_4x16x1_20e_ava_rgb.py --validate
如果使用SlowFast官方的框架进行训练,则不需要*_proposals_*.pkl,而需要frame_lists目录下的train.csv和val.csv
根据官方文档进行环境配置https://github.com/facebookresearch/SlowFast/blob/main/INSTALL.md 跟着官方步骤会报错,解决方法参考https://blog.csdn.net/y459541195/article/details/126278476
将前文得到的数据集整理成如下格式
- ava
- frames
- video
- frame
- video
- frame_lists
- train.csv
- val.csv
- annotations
- train.csv
- val.csv
- train_excluded_timestamps.csv
- train-excluded_timestamps.csv
- action_list.pbtxt
- frames
此外,还需要一个ava.json文件存储动作类别,格式如下
{
"point at": 1,
"attack": 2,
"uncivilized posture": 3,
"destroy": 4,
"smash": 5,
"stand": 6,
"sit": 7
}TRAIN:
ENABLE: True
DATASET: ava
BATCH_SIZE: 4
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 2
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: #预训练模型
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 8 # 这里要和预训练模型对应
SAMPLING_RATE: 8 # 这里要和预训练模型对应
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
PATH_TO_DATA_DIR: # ava路径
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
BGR: False
DETECTION_SCORE_THRESH: 0.8
FRAME_DIR: # frames路径
FRAME_LIST_DIR: # frame_lists路径
ANNOTATION_DIR: # annotations路径
TRAIN_GT_BOX_LISTS: ["train.csv"]
TRAIN_PREDICT_BOX_LISTS: []
TEST_PREDICT_BOX_LISTS: ["val.csv"]
EXCLUSION_FILE: train_excluded_timestamps.csv
LABEL_MAP_FILE: action_list.pbtxt
GROUNDTRUTH_FILE: val.csv
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 7
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 50
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
BASE_LR: 0.4
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MAX_EPOCH: 100
MODEL:
NUM_CLASSES: 8
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: # 输出路径
TENSORBOARD:
ENABLE: True
LOG_DIR: # tensorboard log路径
CLASS_NAMES_PATH: # ava.json